背景动机
海外App 用户分布在 175 个国家,反馈来自 App Store、Google Play 和邮件三个渠道,每天十来条,七十多种语言。靠人工打开后台,逐条翻译,手动归类整理效率太低。
主要的问题有两个。一个是某个版本上线后评分开始掉的时候,没有办法快速回答「到底是哪个功能、哪个地区、哪个版本引发的集中不满」。数据散在三个地方,没有统一结构,只能靠记忆拼凑。另一个是,这些反馈如果一直是非结构化的原始文本,后续想做数据分析或用来训练 AI 助手,基本没法用。
所以这个项目就是把反馈数据变成可查询、可筛选、可聚合的数据资产,同时为后续的 AI 助手和数据分析打基础。
它现在每天在做什么
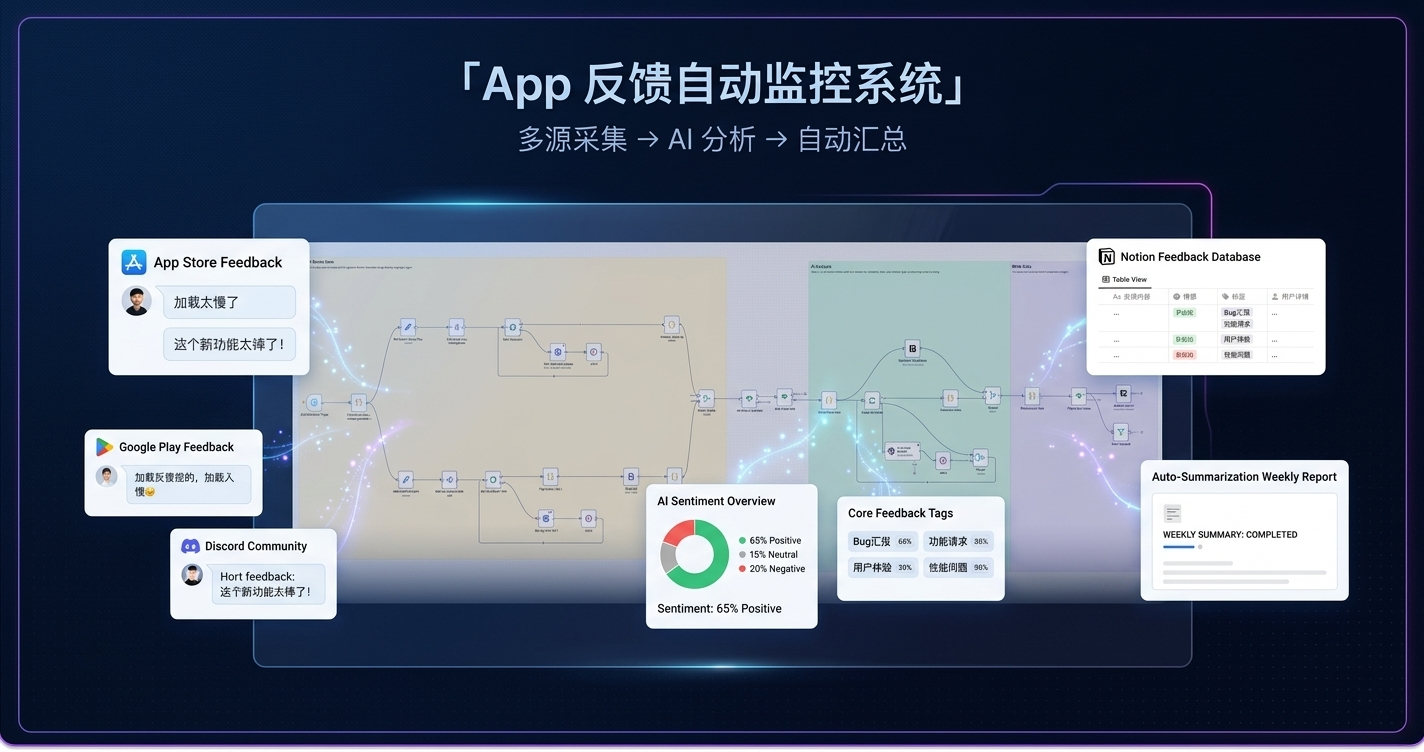
三条数据流——App Store 评论(RSS Feed,覆盖 175 个国家)、Google Play 评论(API,76+ 种语言)、用户邮件反馈(Google Sheets 中转)——每天凌晨自动触发,汇入同一套分析管道。
每条反馈经过清洗和去重后,由 AI 打上情感标签(5 级)、意图分类(10 类)、功能模块归属(12 类)和优先级(P0–P4),然后写入 Notion 数据库。低评分条目单独标记。
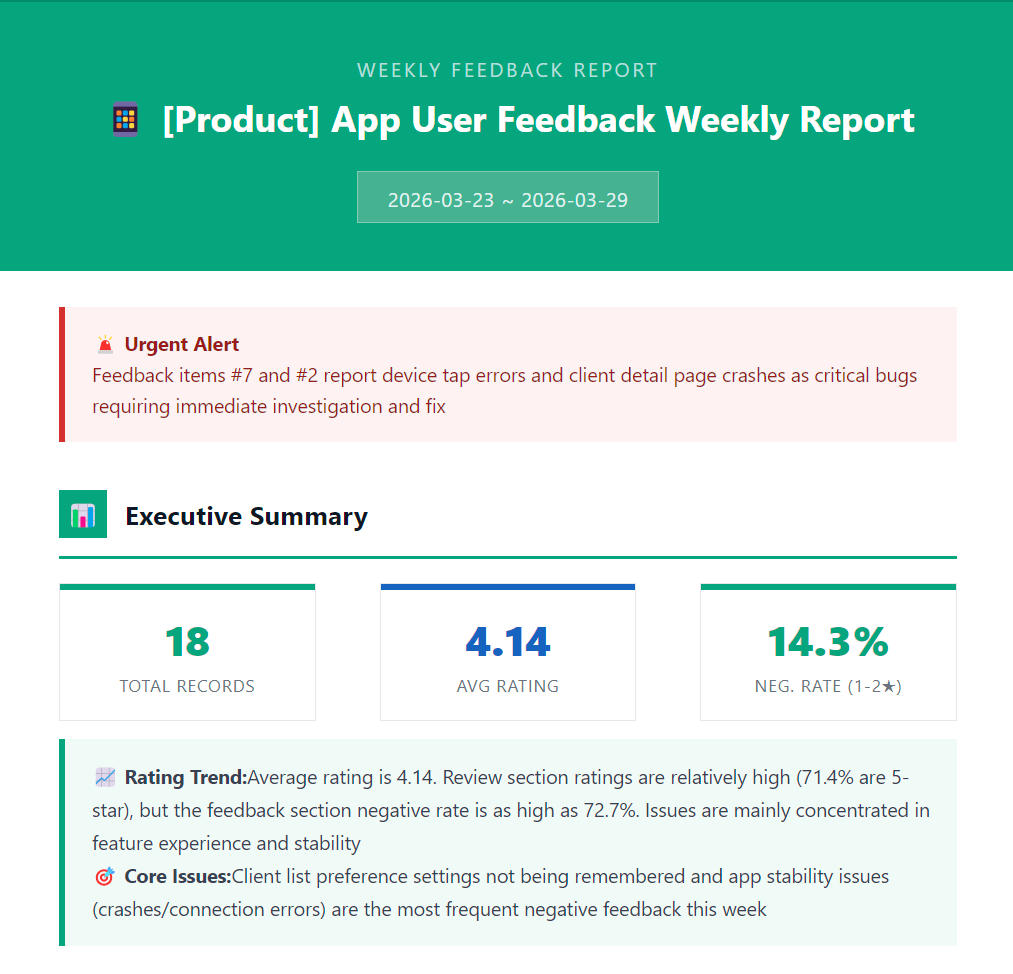
日常使用方式很简单:打开 Notion,按国家、版本、情感、功能模块任意组合筛选。每周还会自动生成一份数据洞察周报,汇总本周的情感分布、热点功能模块、低评分趋势等关键指标,定时发送给团队。
实现路径
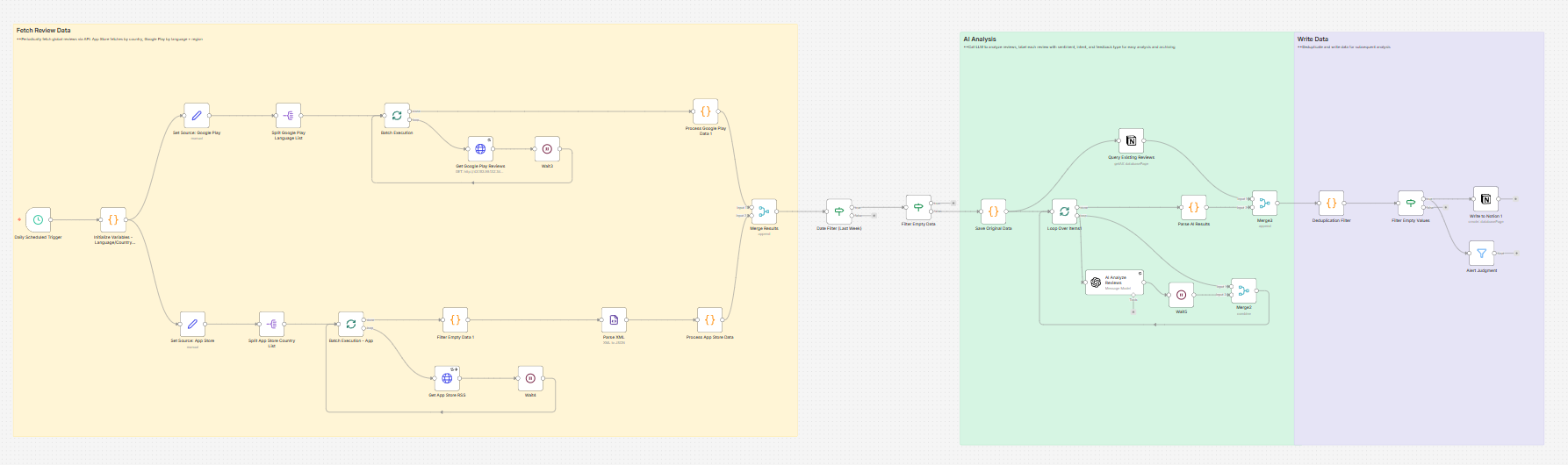
工具选型:n8n。 这套系统的数据源和分析逻辑都在持续变化——会加新渠道,分类标准会调整,prompt 会迭代。纯脚本维护起来太累,n8n 的可视化画布让每个节点的中间数据可以直接查看,改动成本低很多。也看过 Dify、Coze 这类低代码平台,但 n8n 的生态更丰富,自定义配置的空间大很多,操作复杂一点但值得。
架构原则:三条流进来,分析逻辑只写一次。 三个数据源格式完全不同,但在进入分析管道前统一成同一个 JSON 结构。这样 AI 分析、去重、写入 Notion 这些环节只需要维护一份逻辑。后续如果要接 Reddit 或其他社区数据,只需要加一个入口节点做格式转换。
踩过的坑
Google Play 的评论接口只支持按语言拉取,不支持按国家。一开始按国家维度去请求,拿到的评论一直不全,排查了几天才定位到是接口维度的问题。后来重新设计了一套 country → language → region 的映射表,把 200 多个国家代码对应到语言和地区分组。这个映射关系反而成了报告里「地区聚合」维度的基础。
邮件反馈表面上格式固定,实际处理起来最复杂。HTML 邮件模板有两种结构,字段位置不完全一致,需要写两套正则分别提取设备型号、App 版本、固件版本等 20 多个字段。另一个没预料到的问题是去重——不少用户在没收到回复时会反复提交内容几乎一样的反馈。基础的内容哈希去重不够,后来加了一层 LLM 语义判断,让它识别同一用户的不同表述是否在描述同一个问题。加上这一层之后,Notion 里的数据噪声明显下降。
当前状态与下一步
这套工作流目前仍在每天自动运行,已经稳定跑了几个月,累计处理了五百多条反馈。
下一步打算在这套数据基础上做两件事:一个是可视化的监控看板,把趋势和分布直接展示出来;另一个是接入 AI 对话能力,不用手动拼筛选条件,直接问「总结上个月的反馈趋势」或者「昨天的差评集中在哪个功能」就能拿到答案。
工作流 JSON 和完整的 README 已整理上传到 GitHub,包含占位符替换说明,可以直接导入 n8n 使用。