
环境就是一台 Mac Mini M1 16GB,OpenClaw 本地部署,模型用 MiniMax + Gemini,Discord 和飞书做交互入口。最近加了微信,但效果不是很好,卡片和表格效果渲染不出来。
第一层:信息抓取流水线
这是最早搭的部分,解决"每天要手动刷好几个平台"的问题。
信息源: Reddit、X、Product Hunt、Hacker News、GitHub Trending
抓取方案:
- Reddit API还没申请到和 X API有点小贵,主要用持久化 Chrome + CDP(Chrome DevTools Protocol)远程控制,保持登录态定时跑
- Product Hunt 走官方 API
- Hacker News 和 GitHub Trending 直接用 RSS 抓取
处理链路:
- 7:00 — 刷新登录态(部分平台 cookie 会过期)
- 8:30 — 抓取 + MiniMax 分析(摘要、分类、相关度打分)
- 写入 Notion 两个数据库:「AI 第二大脑」存原始素材,「商机洞察」存经过筛选的高相关度内容
- 18:00 — 飞书推送日报
踩过的坑:
- X 的反爬比较激进,CDP 控制的 Chrome 需要模拟真实滚动和停留时间,不然容易触发验证
- 微信公众号还在研究怎么抓比较稳定,暂时没接进来
- Notion API 写入有速率限制,批量写入时需要做队列和重试
这一层跑通之后,"每天花一两个小时刷信息"这件事就被接管了。但随之而来的问题是:流水线本身是死的,不会根据反馈调整。
第二层:记忆管理——让 Agent 记住上下文
这是我花时间最多的一层,也是体感改善最大的一层。
问题
OpenClaw 原生的记忆机制存在几个实际问题:
- Context window 满了之后做 Compaction,很多具体数值、路径、配置会在压缩中丢失
- Session 切换后工作状态断裂,上一轮的决策和中间结果拿不到
- 时间一长,向量记忆库里重复条目、过时条目、互相冲突的条目越来越多,检索质量下降
解决方案:三个机制分别处理「存」「清」「防丢」
① ByteRover——结构化记忆存储与检索
社区技能包,核心思路是把扁平的 Markdown 记忆重组为层级树结构。
具体实现:
- 每个记忆节点有父子关系、时间戳、来源标注
- Context 快满时,关键内容被 curate 进树的对应节点
- 每天从 session notes 中提取规律性内容,写入持久层
- 每次 prompt 前通过 hook 自动注入与当前话题相关的记忆片段
② memory-hygiene——定期清理向量记忆
这个技能包专门做记忆审计,解决的是"记忆越来越多但质量越来越差"的问题。
运行逻辑:
- 每周日自动扫描向量记忆库
- 语义相似度 > 90% 的重复条目,合并或删除
- 超过 30 天未被检索引用的条目,标记为候选清理项
- 检测到互相冲突的条目时,保留较新的那条,旧的归档
- 生成清理报告,确认后批量执行
这一步不做的话,两个月之后记忆库基本就是噪音大于信号。
③ memory-wal——防止 Compaction 丢数据
这个是我自己写的,借鉴了数据库 WAL(Write-Ahead Logging)的思路。
核心机制:
- 消息中出现数值、路径、配置、决策等关键信息时,先写入
SESSION-STATE.md再回复 - Compaction 发生后,按三步恢复:读 STATE → 读 daily log → memory search
- 只有发现矛盾时才停下来让我确认,否则自动恢复
- STATE 文件限制 50 行,每晚 22:00 自动归档到 daily log
第三层:错误捕获与规则固化
记忆解决了"记住"的问题,但还有一个问题:同样的错会反复出现。Agent 记住了你的偏好,不代表它每次都会遵守。
机制 1:self-improving-agent——自动记录错误
社区技能包,下载量 13 万+,逻辑很直接:
- 每次 Agent 犯错或被纠正,自动记录当时的上下文和正确做法
- 写入
.learnings/目录,Markdown 格式,零额外成本 - 后续 prompt 时自动检索相关 learnings 作为参考
不需要我主动做什么,它在后台慢慢积累一套"之前错过的事"的知识库。
机制 2:Boris Loop——纠正即规则化
这个思路来自 Claude Code 创始人 Boris Cherny 的实践:每次纠正 AI 之后,让它立刻更新自己的指令文件。
我在 OpenClaw 上的实现:
- 纠正发生时,Agent 把这次纠正提炼为一条行为规则,写入
evolution/rules.md 每条规则带状态标记和生命周期:
- 🟡 pending — 刚写入,待验证
- 🔴 active — 连续遵守 3 次,升级
- ✅ graduated — 30 天未违反,写入长期记忆
- 📦 archived — 过时或不再适用
示例:
🟡pending | 2026-03-15 | Ed 纠正了日报格式
规则:每次生成日报时,必须先检查 Ed 偏好的格式(列表,非表格),且单次消息不超过 300 字规则库不做生命周期管理的话,两个月就会膨胀到不可维护。
机制 3:五步迭代协议(EVOLUTION.md)
当同类错误出现 2 次以上,或者我主动触发"复盘"时,系统加载完整迭代协议:
- 收集素材 — 回看完整上下文 +
.learnings/最近 7 天记录 - 识别模式 — 跨多次对话找共性,不看单次失败
归因分类:
- A 类:不知道(缺少信息)
- B 类:知道但忘了(记忆机制问题)
- C 类:流程设计问题(需要改机制而不是改规则)
- 制定规则 — 每条必须具体、可验证、可执行,每次最多 3 条
- 持久化 — 写入规则库,标注日期和原因
每周五自动跑一次 review:验证过的规则提升状态,没用的规则归档。
第四层:自动化生长——Growth Loops
这是 proactive-agent 技能包里的核心概念:如果用户连续多次让 Agent 做同一件事,Agent 应该主动建议把它变成自动化。
实际运行效果:
- 我连续 3 天在 Discord 让它查 Reddit 上的用户讨论 → 第三次它主动提议创建定时任务 → 我同意 → 它调用 Cron 功能自动建好
- 从此这件事不用再说
防止过度自我修改:VFM 评分
一个会自己改自己配置的系统,很容易改乱。proactive-agent 里有一个 VFM(Value-per-File-Modified)评分机制:
- 每次 Agent 想修改自己的配置文件,先给这次改动打分
- 低于阈值的改动直接跳过
- 避免"为了优化而优化"的无效修改
两个月下来,系统从最初的 3个定时任务,自然增长到8个:每周五复盘提醒、重复信息整理、日常巡检。都不是一开始设计好的,是用着用着长出来的。
架构全景
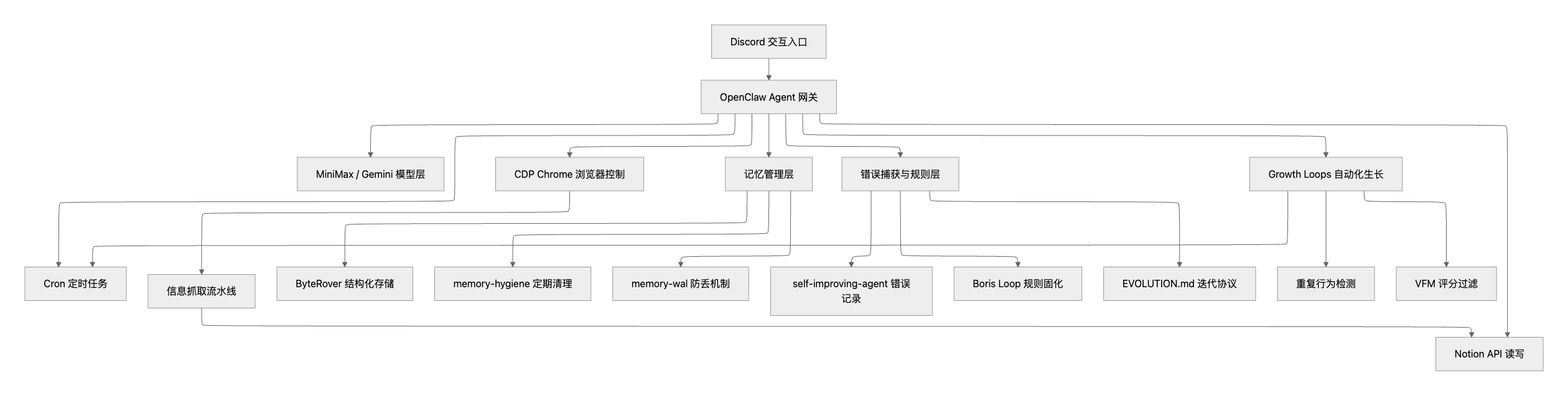
可复用的几个判断
什么时候该补记忆机制: Agent 开始反复忘记你说过的事,或者 Compaction 之后上下文明显断裂。
什么时候该补错误捕获: 你发现自己在纠正同一类问题第三遍以上。
什么时候该补自动化建议: 你意识到自己每天在"手动维持自动化"——让一个自动化系统做事,但触发本身还是手动的。
什么时候不该急着加东西: 系统刚跑起来的第一周。先让它跑,先记录哪里不顺,再动手。过早优化和过早加机制一样,都会把系统搞复杂但没解决真正的问题。
还没解决的问题:上下文管理
前面几层做完之后,记忆能存能清,错误能捕获能固化,重复动作能自动接管。但有一个问题一直没动:OpenClaw 原生的上下文注入机制。
现在每次发起对话,OpenClaw 会把记忆、规则、session 状态、learnings 全部塞进 context。不管你问的是"今天日报发了没"还是"帮我分析一下这个竞品的定价策略",注入的背景信息量几乎一样。随便一轮对话,上来就带着上万 token 的上下文。
这带来两个实际问题:
- 注意力稀释:context 里噪音越多,模型对真正相关信息的关注度越低。问一个简单问题,回答质量反而不如不带记忆的裸模型
- 上下文腐烂:随着记忆和规则越积越多,即使 memory-hygiene 定期清理,注入总量还是在涨。ByteRover 优化了检索相关性,但注入策略本身没有区分场景——该注入多少、注入哪些,这一步是缺失的
打算做的方向
准备看看能不能在 OpenClaw 的上下文管理层加一个分级注入机制:
- 根据当前消息的复杂度和话题,动态决定注入哪些类型的记忆(偏好、规则、工作状态、历史 learnings)
- 简单查询类对话,只带最小必要上下文;涉及多步决策或需要历史背景的任务,再拉完整记忆
- 可能需要在 prompt 前加一个轻量的分类步骤,或者用 token 预算的方式做硬约束
具体方案还没定吗,先观察一段时间看看。关键在于"什么时候需要什么记忆"本身就很难预判——我觉得一个简单问题不需要上下文,但AI不觉得,甚至恰好是某条历史规则决定了回答的格式。砍多了会退化,砍少了没效果。
参考资料
本文涉及的工具和社区技能包: